

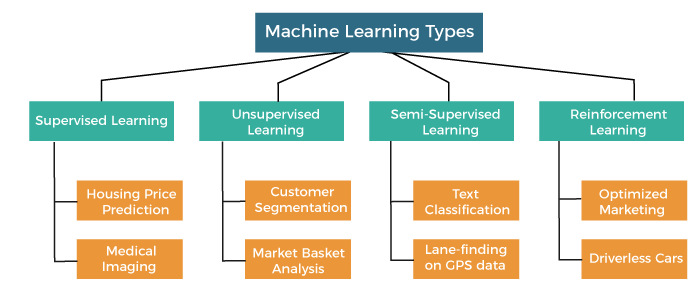
Semi-Supervised Learning in Machine Learning

Semi-Supervised Learning in Machine Learning

Understanding Semi-Supervised Learning in Machine Learning
Semi-supervised learning is a powerful machine learning paradigm that combines the strengths of both supervised and unsupervised learning. It uses a small amount of labeled data along with a large pool of unlabeled data to improve model performance.
It is especially useful in scenarios where the cost of acquiring labeled data is too high or time-consuming, but unlabeled data is readily available.
What is Semi-Supervised Learning?
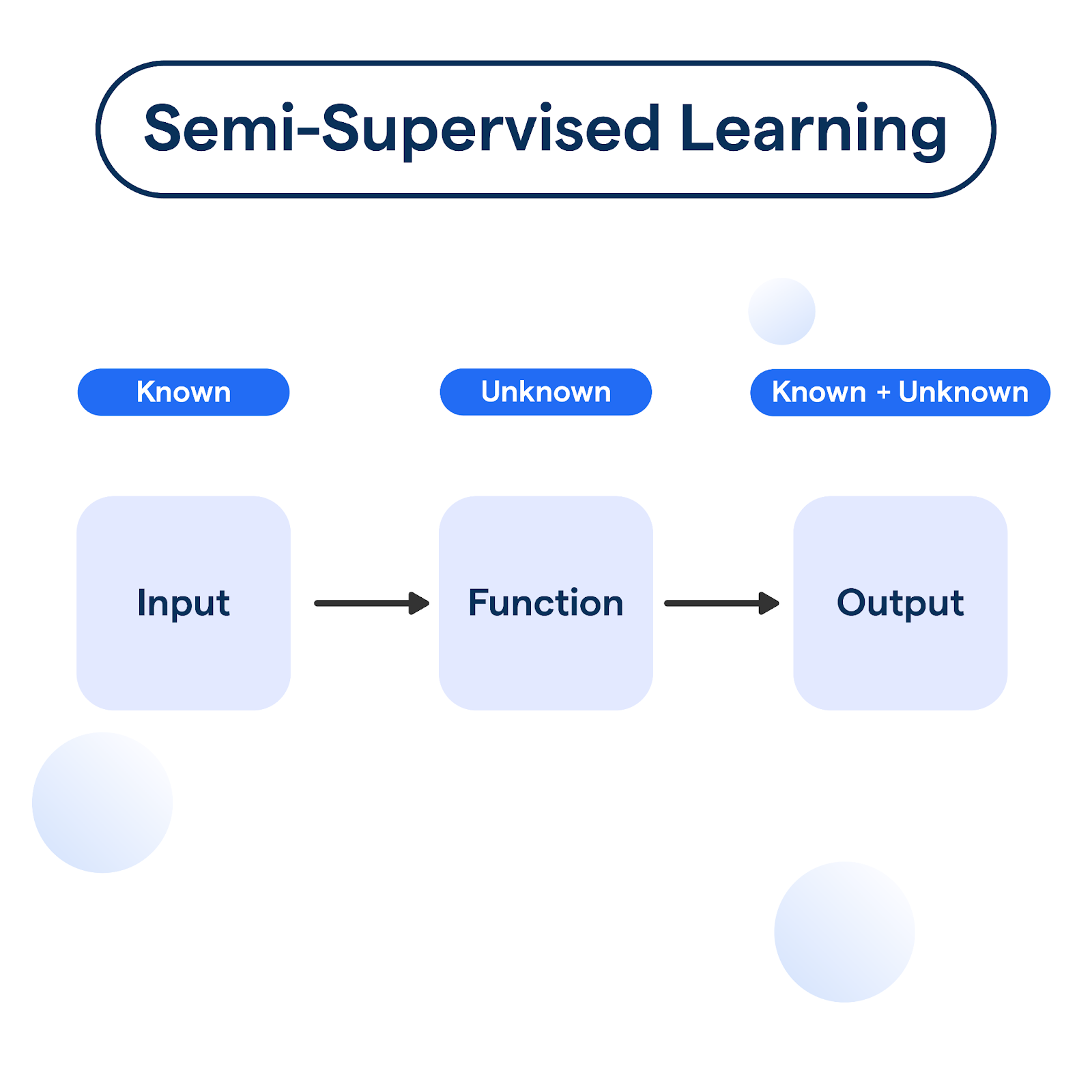
Semi-supervised learning falls somewhere between supervised and unsupervised learning. In supervised learning, models are trained solely based on labeled datasets where an input is accompanied by a correct output. Unsupervised learning handles datasets without labels, instead finding the patterns or structures in the data. SSL takes advantage of both the data types to enrich the learning process, making the model generalize better from very few labeled examples while extracting more information from the unlabeled data
How Does Semi-Supervised Learning Work?
The semi-supervised learning process usually includes the following steps:
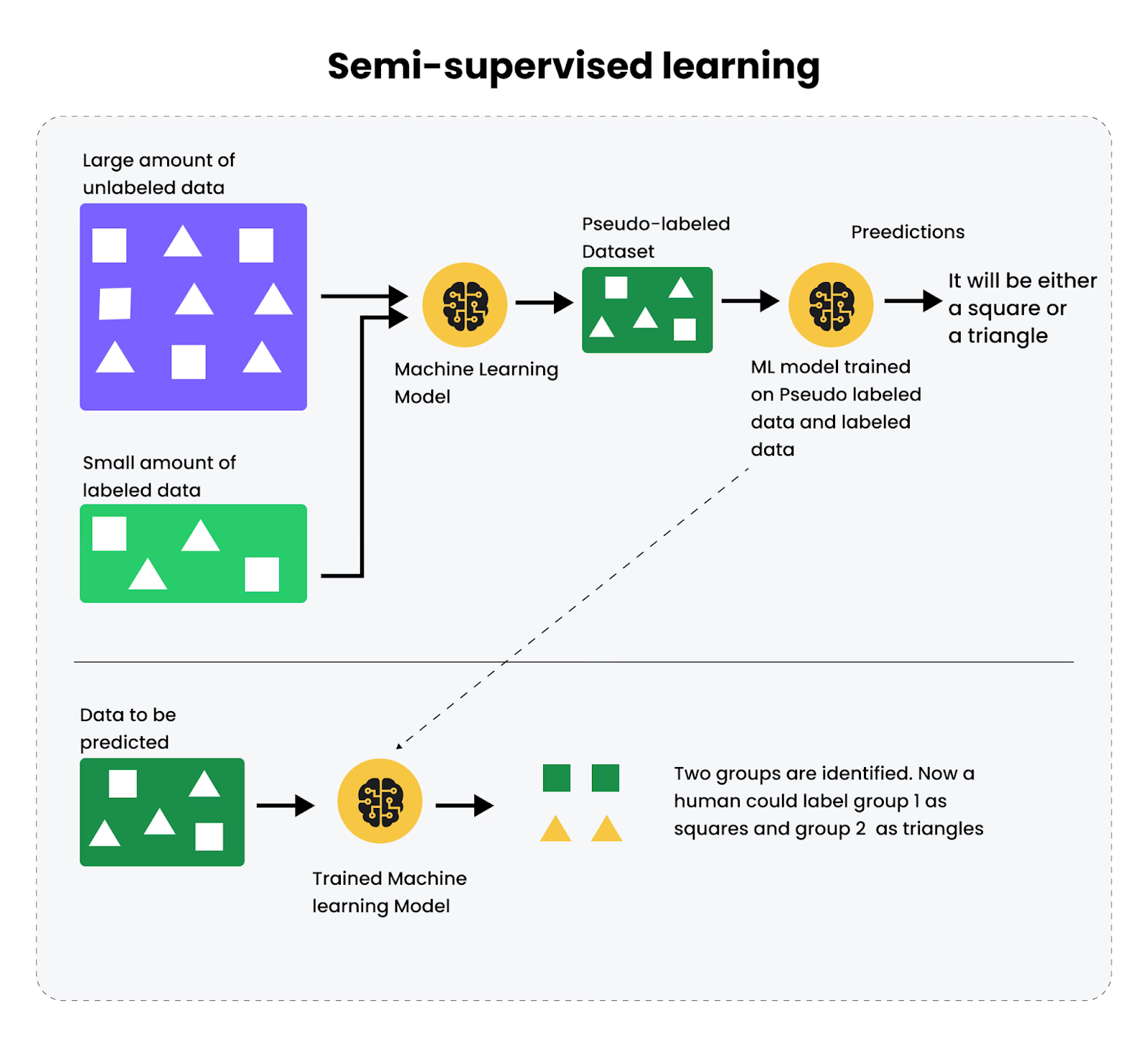
Data Collection: Start with a small set of labeled data and a much larger set of unlabeled data.
Initial Training: Train a model using the labeled data to create a baseline understanding.
Pseudo-Labeling: Use the trained model to predict labels for the unlabeled dataset. These predictions are called pseudo-labels.
Refinement: Combine the original labeled data with the newly pseudo-labeled data and retrain the model to increase accuracy and robustness
Techniques in Semi-Supervised Learning
Several techniques are employed in semi-supervised learning
- Self-Training
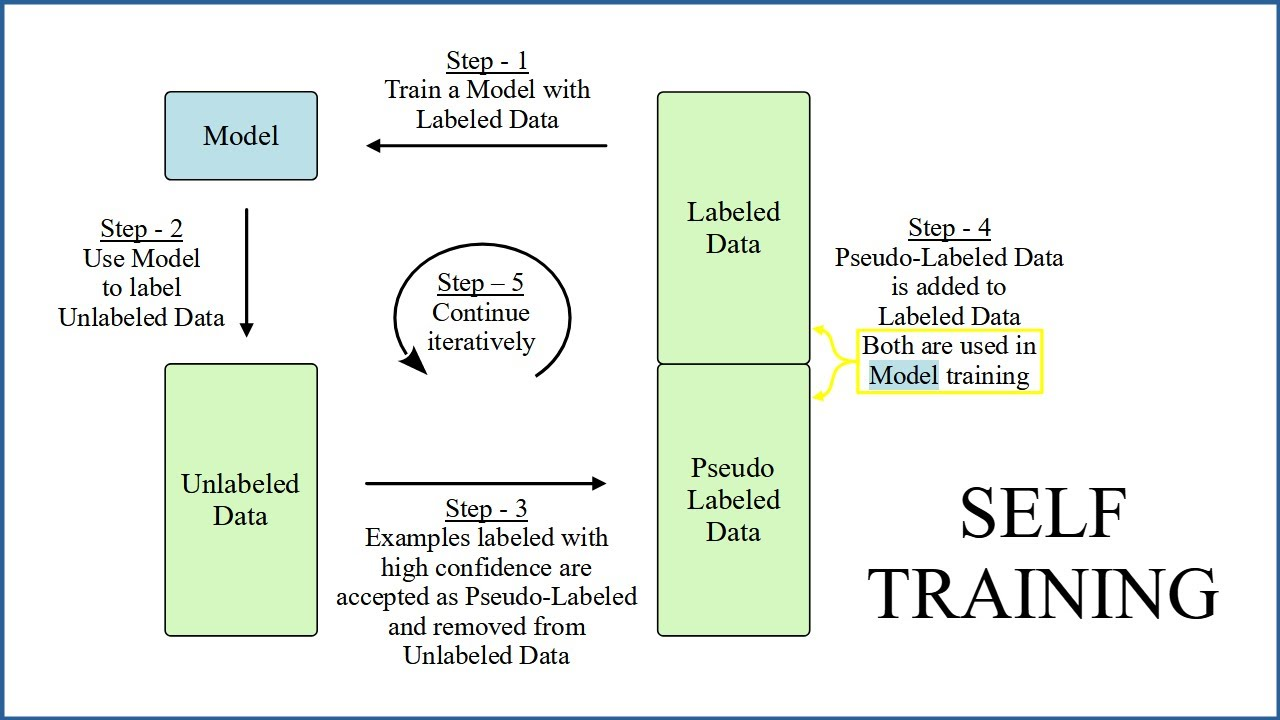
The model is trained on labeled data initially, and then used iteratively to generate labels for unlabeled data, fine-tuning its predictions in cycles until it converges.
- Co-Training
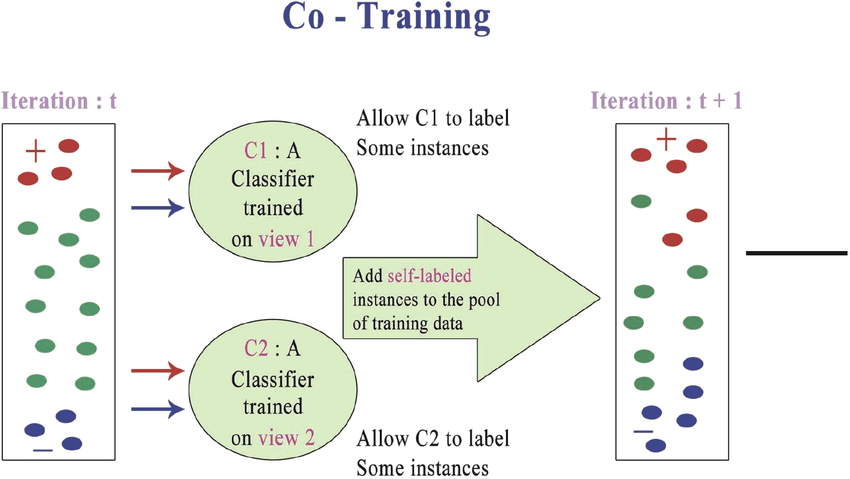
Two models are trained together on different feature subsets from the same data. Each model generates class assignments for the unlabeled data set to train the other. This approach assumes that different models are capable of capturing complementary information about the data
- Graph-Based Method
These techniques employ graph structures where nodes represent instances (both labeled and unlabeled) and edges represent similarities between them. The idea is to propagate label information through the graph, allowing unlabeled instances to inherit labels from their neighbors
Advantages of Semi-Supervised Learning
Semi-supervised learning has the following important advantages:
- Cost Efficiency: This technique decreases the amount of hand-labelling required, which might be a time and labor-consuming process. Unlabeled data can be used very productively, saving time and costs and yet maintaining high accuracy models for an organization
- Better Generalization: As more data is introduced during the training process, patterns and underlying structures get digested better by models for predictions to be made on events that have fewer labeled examples
- Flexibility: SSL can be applied across different domains and tasks, such as classification, regression, and clustering, making it a versatile tool in machine learning
Applications of Semi-Supervised Learning
Semi-supervised learning has found applications in many fields:
- Natural Language Processing (NLP): SSL techniques are widely used for tasks such as text classification and sentiment analysis, where large amounts of text data are often available without labels.
- Image Classification: SSL is used to improve image classification models in computer vision through the use of many unlabeled images and only a few labeled samples.
- Medical Diagnosis: In medicine, SSL can be applied in diagnosing diseases. Here, the method uses very few labeled medical records and vast amounts of patient data.
Understanding Semi-Supervised Learning: How It Works
Semi-supervised learning, or SSL, is a form of machine learning that sits in between supervised and unsupervised learning. This is because SSL combines small amounts of labeled data with larger amounts of unlabeled data to enhance learning accuracy. It's the best choice when the process of labeling the data is too expensive or too time-consuming.
How It Works
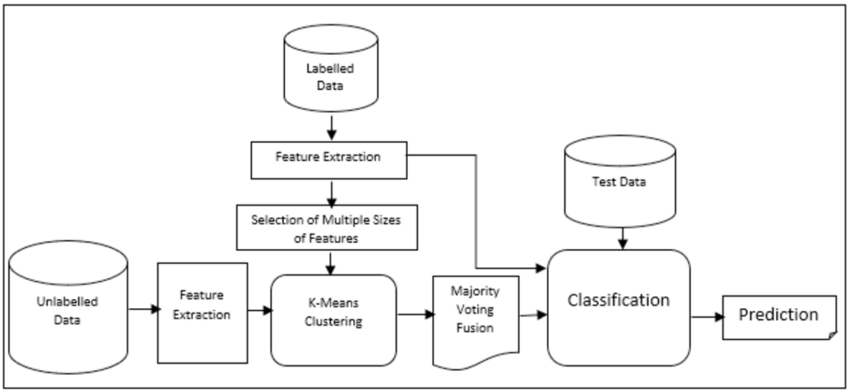
- Initialization with Labeled Data
It first trains a model on the labeled data available. This step gives an initial insight into the patterns present in the dataset.
- Leveraging Unlabeled Data
The learned patterns are then used by the model to make predictions on the unlabeled data. Self-training, consistency regularization, or graph-based methods can be used to get pseudo-labels for the unlabeled data.
3.Iterative Refinement
The pseudo-labeled data is combined with the original labeled data, and the model is retrained. This cycle repeats iteratively, enhancing the model's understanding and performance.
4.Final Model
Through continuous learning, the model refines its predictions and achieves a level of accuracy comparable to using fully labeled data.
Semi-supervised learning effectively maximizes the value of available data, making it a powerful tool in domains like image recognition, natural language processing, and medical diagnosis.For more insights on machine learning techniques, visit DataScienceStop.
Conclusion
Semi-supervised learning is an important advancement in machine learning methodology that bridges the gap between supervised and unsupervised approaches. As it can leverage both labeled and unlabeled datasets, this approach promotes more powerful model training while decreasing the cost of manual labeling. As research in this field continues to evolve, SSL is sure to unlock new opportunities in various applications of artificial intelligence and beyond.
References
Understanding Semi-Supervised Learning: Bridging Labeled and Unlabeled Data
What is Semi-Supervised Learning? A Guide for Beginners - Roboflow Blog





