

Unlocking the Power of Unsupervised Learning: Translating Data into Insights

Unlocking the Power of Unsupervised Learning: Translating Data into Insights

Imagine a world in which machines automatically discover hidden patterns and insights within large amounts of data without needing human intervention. It's not science fiction but rather a wonderful world of unsupervised machine learning.In the era where data is everywhere but labeled information is hard to come by, unsupervised learning has emerged as an important tool in the data scientist's arsenal.
What is unsupervised Machine learning ?
But what exactly is unsupervised machine learning, and why is this such a thing in the world of technology? It doesn't like its supervised counterpart to rely on pre-labeled data, which allows for the making of predictions.
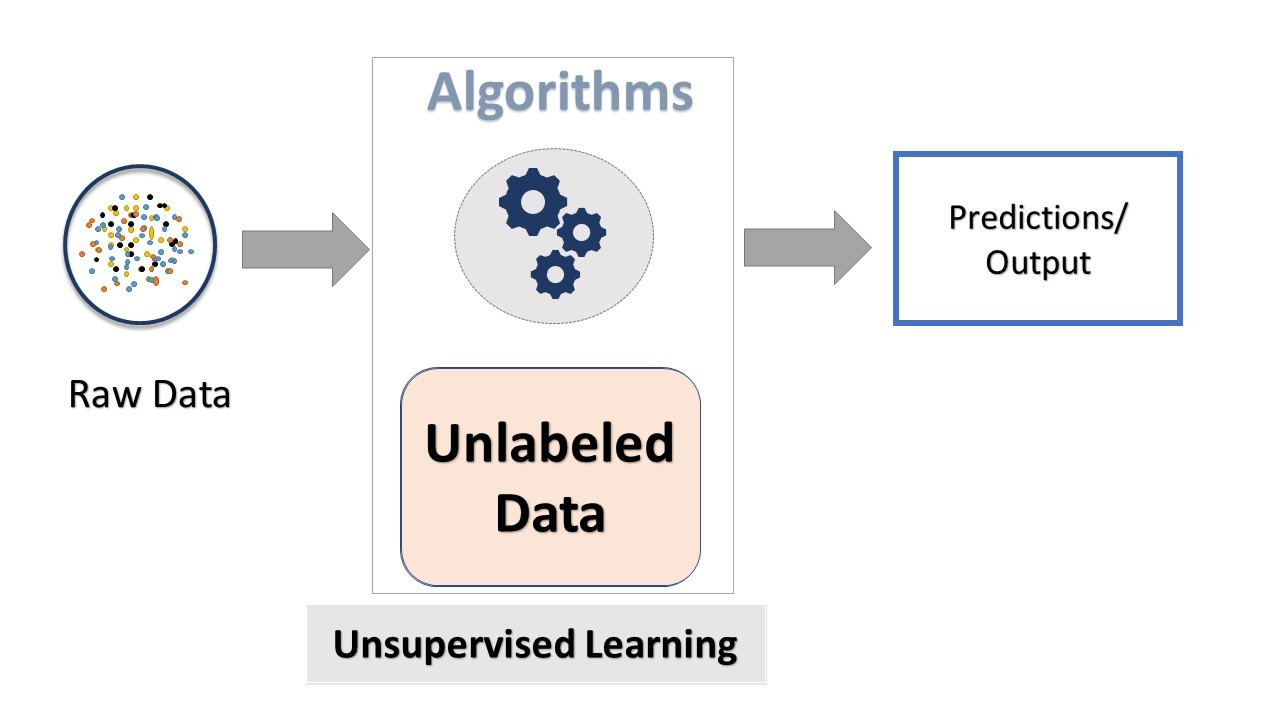
It is more focused on exploration and discovery: exploring and discovering intricate relations in the dataset, allowing for the extraction of patterns and structures otherwise hidden within it.
This could range from clustering similar customer behaviors to discovering anomalies in complex systems. The applications are just as diverse and groundbreaking as the underlying idea.
Detailed information on Unsupervised Learning
We are going to dive deep into the world of unsupervised machine learning. We will get to know its basic concepts, discuss various types of algorithms, and find the benefits and challenges of this cutting-edge approach.
On top of that, we will look at some pretty interesting real-world applications revolutionizing industries around the world.Let's get ready to unlock the potential of your data and see how unsupervised learning is shaping the future of artificial intelligence!
Types of Unsupervised Learning Algorithms
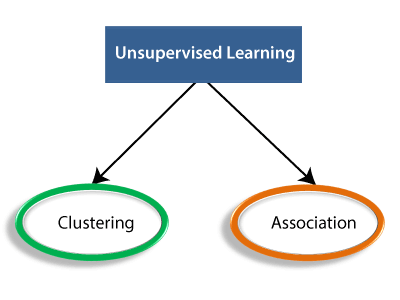
Having established a comprehensive understanding of unsupervised machine learning, it will now be able to explore the numerous types of algorithms found in this field. These will find hidden patterns and structures in unlabelled data, making them very useful for many applications.
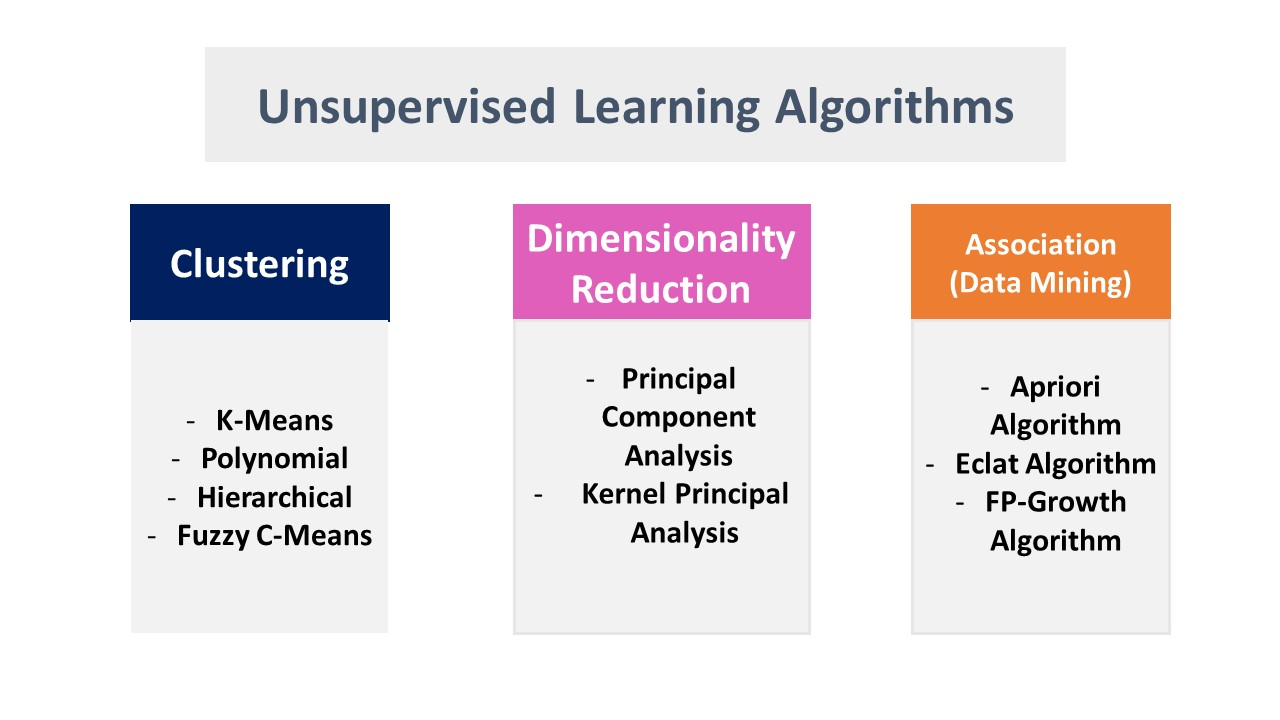
1.Clustering Algorithms
Algorithms for clustering is the foundation of unsupervised learning. Algorithms bring data points together to a group depending on its internal characteristics.
The widely applied algorithms include the following.
1.1 K-means clustering
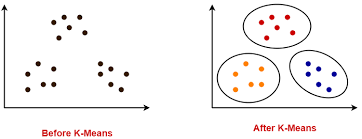
- K-means is a procedure of unsupervised algorithm for machine learning where this is implemented to separate any set of data into k disjoint, non-overlapping clusters.
- It sets the centroids and assigns points to the closest centroid of the assigned points, where it calculates centroids again by only those assigned points.
- This repeats until convergence and reduces the intra-cluster variance.
1.2 Hierarchical clustering
Hierarchical clustering is a cluster analysis technique that constructs a hierarchy of clusters from the data.
It can be divided into two main types: agglomerative (bottom-up) and divisive (top-down).
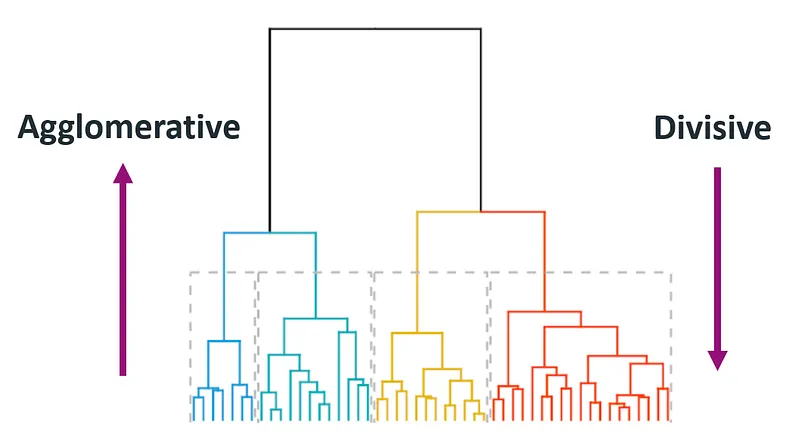
Agglomerative starts with individual data points and merges them into larger clusters, while divisive begins with one cluster and splits it recursively.
The results are often visualized using a dendrogram, illustrating the relationships among clusters.
1.3 Polynomial Clustering
1. Handling high-dimensional data
2. Optimal separation
3. Consensus clustering
4. Applications in biomedical data
1.4 Fuzzy C-Means Clustering
1. Soft approach to clustering
2. Objective to be minimized
3. Noise robustness
4. Extremely wide applications
2. Dimensionality Reduction Techniques
Dimensionality reduction is useful for handling large dimensional data, becoming more manageable and interpretable.
Key methods include;
2.1Principal Component Analysis (PCA)
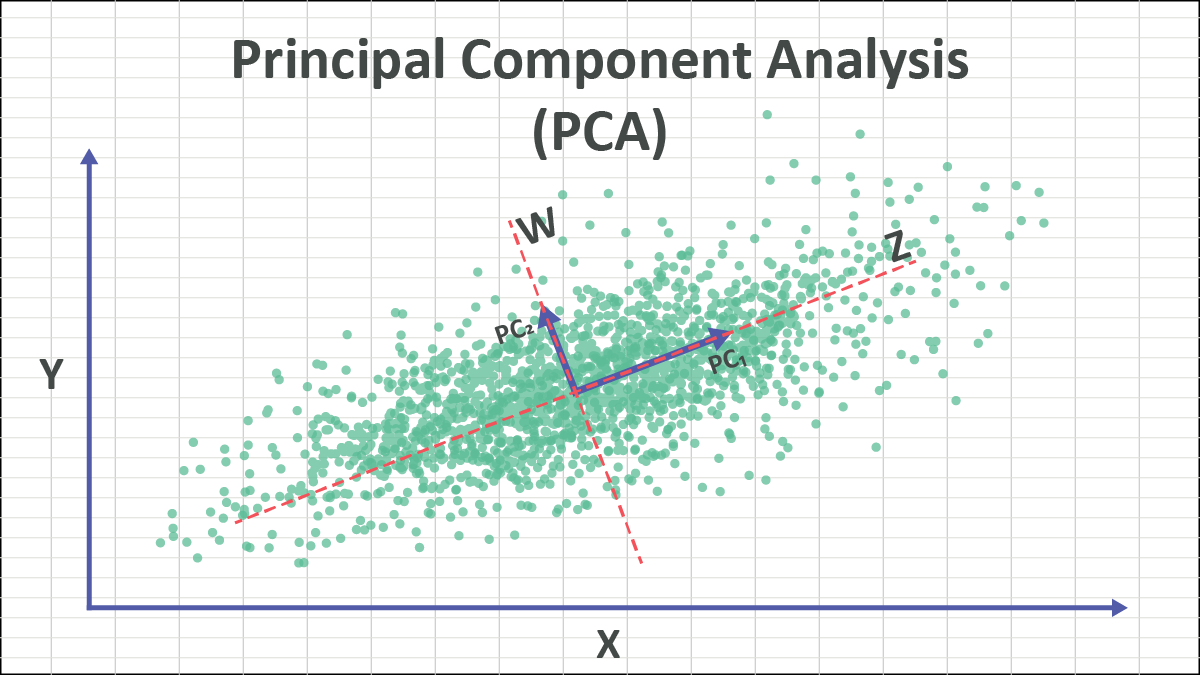
t-SNE: t-Distributed Stochastic Neighbor Embedding
Auto-encoders
Linear Discriminant Analysis (LDA)
These techniques are imperative for pattern detection in the big data with efficient and effective visualization and feature abstraction.
2.2 Anomaly Detection Techniques
Anomaly detection is important, as it provides the capacity to identify peculiar patterns of outliers in the data.
Common techniques
Isolation Forest
One-Class SVM
Local Outlier Factor (LOF)
Elliptic Envelope
These techniques are widely used in fraud detection, network security, and quality control scenarios.
3. Association Rule Learning
Association rule learning finds interesting relations between variables within large databases.
Popular algorithms include:
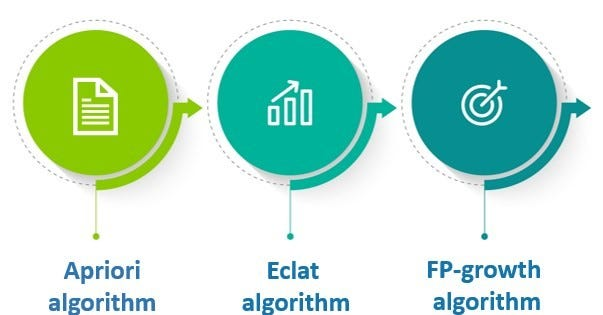
Apriori algorithm
FP-Growth algorithm
ECLAT (Equivalence Class Transformation)
These methods are extensively used in market basket analysis, recommendation systems, and data mining applications.
There are also powerful unsupervised learning techniques like SOMs, which are a combination of approaches by clustering and dimensionality reduction. SOMs create a low-dimensional representation of high-dimensional data while preserving topological relationships.
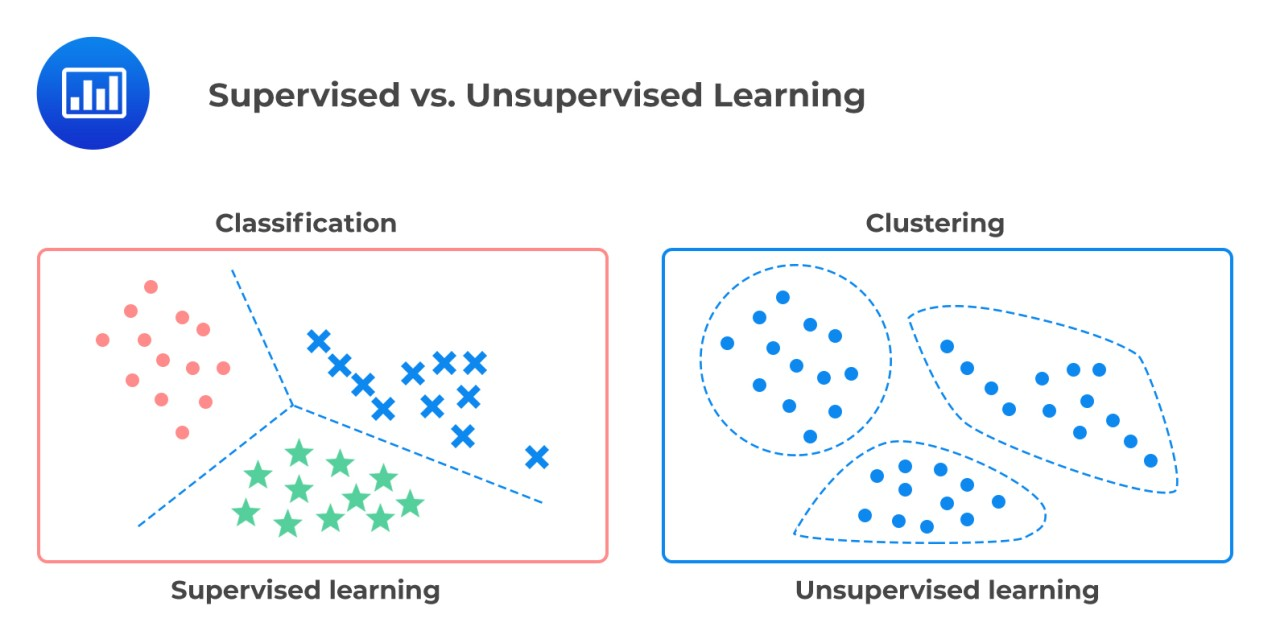
Difference between supervised and unsupervised learning
These diverse unsupervised learning algorithms allow data scientists and machine learning practitioners to discover hidden patterns in complex, unlabeled datasets.
Each of these types of algorithms can be applied to different domains-for example, customer segmentation in marketing or anomaly detection in cybersecurity.As we look ahead, we shall describe the wide benefits of unsupervised machine learning, and how it stands ready to accelerate the strides of data analysis and decision-making across all fields of industries.
Key Benefits of Unsupervised Learning
Unsupervised learning is a powerful subset of machine learning that focuses on analyzing and interpreting unlabeled data in order to discover hidden patterns and relationships. Unlike supervised learning, which relies on labeled datasets, unsupervised learning algorithms autonomously identify structures within the data, making it ideal for exploratory data analysis.
- Data Exploration: Unsupervised learning allows organizations to uncover insights from vast amounts of unlabeled data, thus helping in a deeper understanding of underlying patterns without prior assumptions.
2. Cost-Effective: It eliminates the need for extensive labeling, saving time and resources that would otherwise be spent on data preparation.
3. Pattern Recognition: This approach can identify previously unnoticed relationships in data, leading to valuable insights that inform decision-making.
- Versatility: Unsupervised learning is able to be applied to different kinds of data and problems, thus making it versatile in different industries.
Real-World Applications
- Market Segmentation: Companies use clustering algorithms to segment customers by their purchasing behavior, preferences, and demographics, and this enables them to implement targeted marketing strategies.
2. Anomaly Detection: In finance and cybersecurity, unsupervised learning helps identify unusual patterns that may indicate fraud or security breaches.
3. Recommendation Systems: E-commerce platforms use unsupervised learning to analyze user behavior and suggest products based on similar customer profiles.
- Genomics: In bioinformatics, unsupervised algorithms analyze genetic data to find correlations between genes and diseases, aiding in research and personalized medicine.
How to Learn More About unsupervised Machine Learning?
If you're intrigued by machine learning and want to dive deeper, visit DataScienceStop.com. Our platform offers a wealth of resources on data science and AI, including easy-to-read blogs, expert insights, and a free newsletter packed with updates on the latest trends.
Conclusion
Unsupervised learning offers several benefits where organizations can draw insights from unlabeled data with high efficiency. It has applications in almost every domain, including marketing, healthcare, etc., indicating its applicability and how important it is in the data-driven world. With the constant generation of massive amounts of data, the need to use unsupervised learning will become crucial to ensure a competitive advantage and innovation.





